1.Business Challenge :
A UK-based diagnostic imaging provider needed to operationalize deep learning models for MRI and CT scan analysis across multiple locations and also wanted to develope fully automated image processing pipelines on top of Kubernetes and Argo CD, Calra
Challenges:
- GPU-intensive workloads with inconsistent scaling
- Model performance drift across imaging devices
- Long inference times affecting diagnosis speed
- High cloud cost due to unmanaged GPU usage
- CloudZenSolution :
CloudZen implemented a high-performance, cost-optimized MLOps platform on AWS.
Key capabilities:
- Automated training pipelines for large image datasets
- GPU-optimized inference endpoints
- Canary deployments for new imaging models
- Performance and cost monitoring per model
- Solution Provided byCloudZen Innovations:
CloudZen Innovations designed and implemented a secure, high-performance, and cost-optimized MLOps platform on AWS, purpose-built for large-scale healthcare imaging workloads. The solution enabled the customer to move from experimental AI models to production-grade, clinically reliable deployments while maintaining strict governance and cost control.
Key Capabilities Delivered
End-to-End Automated Training Pipelines
CloudZen built fully automated ML pipelines to handle large-scale medical image datasets (MRI, CT, X-ray). Data ingestion, preprocessing, model training, validation, and registration were orchestrated using AWS-native services, significantly reducing manual intervention and accelerating experimentation cycles.
GPU-Optimized, Scalable Inference Architecture
To meet low-latency diagnostic requirements, CloudZen deployed GPU-backed inference endpoints with intelligent auto-scaling. This ensured consistent performance during peak diagnostic hours while avoiding over-provisioning during low-usage periods.
Safe Model Releases with Canary Deployments
New imaging models were rolled out using canary deployment strategies, allowing a controlled percentage of traffic to be routed to newer models. This enabled real-world performance validation before full rollout, minimizing clinical risk and ensuring patient safety.
Model-Level Performance and Cost Observability
CloudZen implemented continuous monitoring for model accuracy, inference latency, data drift, and GPU utilization. Cost and performance metrics were tracked at a per-model level, giving the customer complete visibility into operational efficiency and enabling proactive optimization.
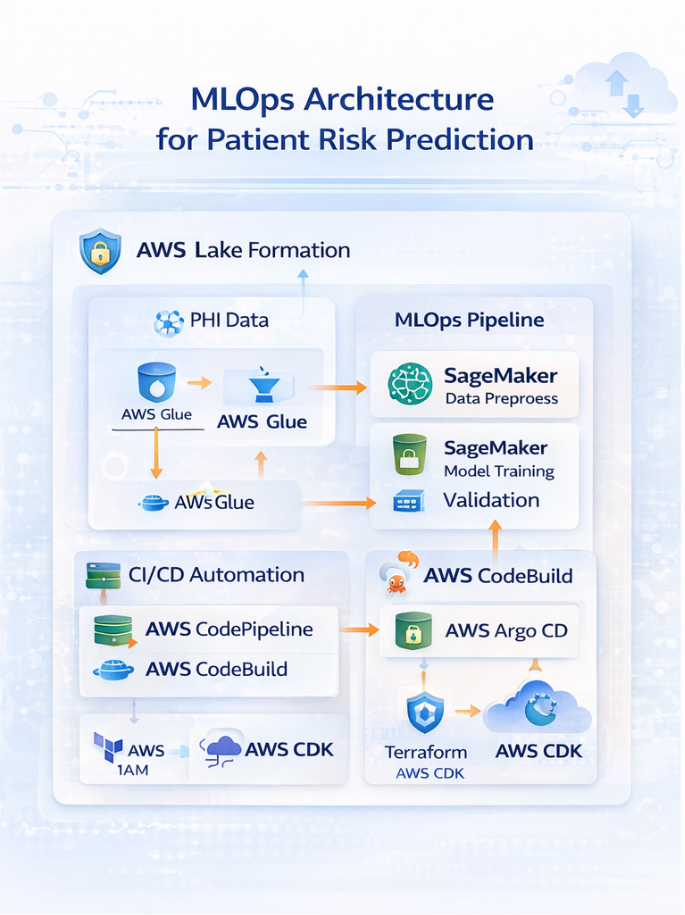
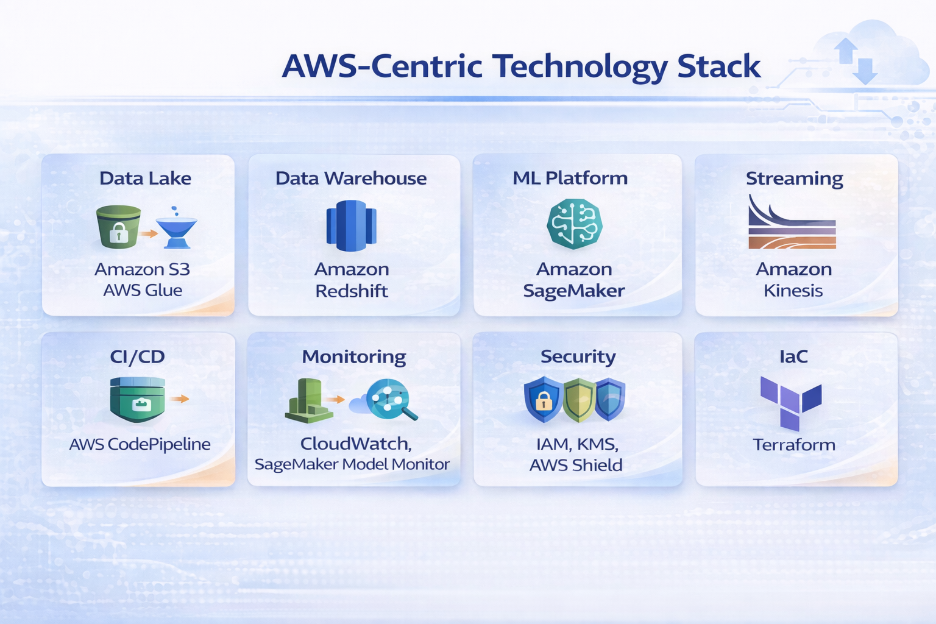
- Technology Stack:
This architecture represents a fully AWS-native MLOps platform designed to support scalable, secure, and automated machine learning workloads. Raw and curated datasets are stored in Amazon S3 and governed using AWS Glue Data Catalog, enabling schema management and metadata-driven data access. Analytical workloads and feature aggregation are supported through Amazon Redshift for high-performance querying.
Machine learning pipelines are built and orchestrated using Amazon SageMaker, covering distributed training, experiment tracking, model versioning, and managed inference endpoints. Amazon Kinesis enables real-time data ingestion for streaming inference and near-real-time model evaluation.
CI/CD automation is implemented using AWS CodePipeline, enabling controlled promotion of models across environments with built-in validation and approval stages. Continuous monitoring is achieved through Amazon CloudWatch and SageMaker Model Monitor, providing visibility into infrastructure metrics, inference latency, data drift, and model quality.
Security and compliance are enforced across all layers using AWS IAM for fine-grained access control, AWS KMS for encryption of data at rest and in transit, and AWS Shield for infrastructure-level protection. The entire platform is provisioned and managed using Terraform, ensuring reproducible, auditable, and scalable infrastructure deployments.
- Business Outcome
By implementing a cloud-native MLOps platform on AWS, CloudZen enabled the customer to operationalize AI at scale with measurable business impact. The solution accelerated model deployment, improved diagnostic accuracy and reliability, reduced infrastructure and operational costs, and increased overall productivity—transforming machine learning from isolated experiments into a dependable, production-grade capability.